- Microsoft Power Automate Community
- Welcome to the Community!
- News & Announcements
- Get Help with Power Automate
- General Power Automate Discussion
- Using Connectors
- Building Flows
- Using Flows
- Power Automate Desktop
- Process Mining
- AI Builder
- Power Automate Mobile App
- Translation Quality Feedback
- Connector Development
- Power Platform Integration - Better Together!
- Power Platform Integrations (Read Only)
- Power Platform and Dynamics 365 Integrations (Read Only)
- Galleries
- Community Connections & How-To Videos
- Webinars and Video Gallery
- Power Automate Cookbook
- Events
- 2021 MSBizAppsSummit Gallery
- 2020 MSBizAppsSummit Gallery
- 2019 MSBizAppsSummit Gallery
- Community Blog
- Power Automate Community Blog
- Community Support
- Community Accounts & Registration
- Using the Community
- Community Feedback
- Microsoft Power Automate Community
- Galleries
- Power Automate Cookbook
- Re: CSV to Dataset
Re: CSV to Dataset
05-03-2022 07:01 AM - last edited 05-03-2022 07:12 AM






- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
CSV to Dataset
Template for converting large CSV files to JSON, then sending the data to a table or list.
This get data for CSV works even if there are commas in the CSV data. The only requirement is the the CSV file must follow the standard of placing double quotes “ , “ around any item eith in-data commas.
(If you can export as a semicolon, tab, or other delimited file, then you can probably just use a simpler method like Paul’s here: https://www.tachytelic.net/2021/02/power-automate-parse-csv/?amp)
For more information on the delimiter change piece, visit this previous post:
To make a flow to send any CSV data to a new Excel table with given CSV header names without any column mappings, check this template:
https://powerusers.microsoft.com/t5/Power-Automate-Cookbook/CSV-To-New-Excel-Table/m-p/1826096#M964
*Copying the template into an existing flow may create issues with expressions. You may need to copy the rest of your existing flow into the CSV template flow, then move the template scope where you need it.
Version 3 Uploaded 04/09/2022
(More minor fixes & additions.
I adjusted several expressions so it can now handle a few more scenarios with arrays in the CSV data. It should handle any array that doesn't include double quotes and any array that is all strings with double quotes, so ["String1", "String2", "String3"], but it will have issues if it is a mixed array with some double-quoted strings and some other values, for example ["String", 4, 03/05/2022, "String2"] won't work.
I also adjusted how the LineBreak setting is set-up so it now uses the /r/n for the LineBreak. I also provided this link in the flow so anyone can look up the right string for the decodeUriComponent expression(s) if they happen to have different LineBreak characters. This change also made it possible to differentiate between in-data line-breaks and CSV row line-breaks on the files I tested, so it should now replace the in-data line-breaks, like the multiple-choice fields some sites use, with semi-colons. That should make those records much easier to deal with & parse in later actions.
I also looked over a problem with in-data trailing commas. I added a line in the settings where anyone can toggle whether they want it to adjust for trailing OR leading commas in the data, it just can't handle both in one dataset. So if one column in one row has ",String1 String2" and another column in another row has "String 3 String4," then it will have errors.)
Google Drive Link To Download: https://drive.google.com/file/d/1X6BGhXWSnZtFgUK0v-5bHo7RuKSNjNtV/view?usp=sharing
(Older) Version 2 Uploaded 03/26/2022
(Adjusted the 1st Select input so it can now also deal with in-data commas in the 1st column. Added more lines to the 1st Select so it can now handle up to 50 columns with commas in them.)
Google Drive Link To Download: https://drive.google.com/file/d/1UVEewW9J1m9wvSppgFrf7rs3H3txSPUN/view?usp=sharing
Update 06/01/2022
Microsoft Power Platform & Paul Murana recently did a video demonstration of how to handle CSV & other files in dataflows: https://youtu.be/8IvHxRnwJ7Q
But it will only output to a Dataverse or Dataverse for teams table.
If you have any trouble with the standard legacy flow import method, you can also try an alternate Power Apps Solution import method here: Re: CSV to Dataset - Page 8 - Power Platform Community (microsoft.com)
Thanks for any feedback,
Please subscribe to my YouTube channel (https://youtube.com/@tylerkolota?si=uEGKko1U8D29CJ86).
And reach out on LinkedIn (https://www.linkedin.com/in/kolota/) if you want to hire me to consult or build more custom Microsoft solutions for you.
watch?v=-P-RDQvNd4A
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I was able to recreate the double delimiter issues by manually adding quotes to each of the header cells.
There is a part of the flow that replaces any "," with ",," because it needs both a quote-comma and a comma-quote to split the text in the Reformat file data action and replace the in-data commas. So I adjusted that to replace any "," with #_4#",,"#_4# so I can easily identify & adjust any of those back to a single delimiter in the later Reformat back to CSV action without messing up any instances where there really is a ",," signifying a blank value between two comma-containing values.
And the extra comma in some of those values was from a part of an expression that handles a much rarer edge-case, so I removed that expression.
Try the V3.2 and again, thanks for being patient here & helping to improve this for anyone else.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That seems to have done it!


Great solution and I appreciate you taking the time to help me make it work!
Cheers
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@takolota So thank you again for this awesome bit coding CSV to JSON v3.2 - it almost worked for my dataset.
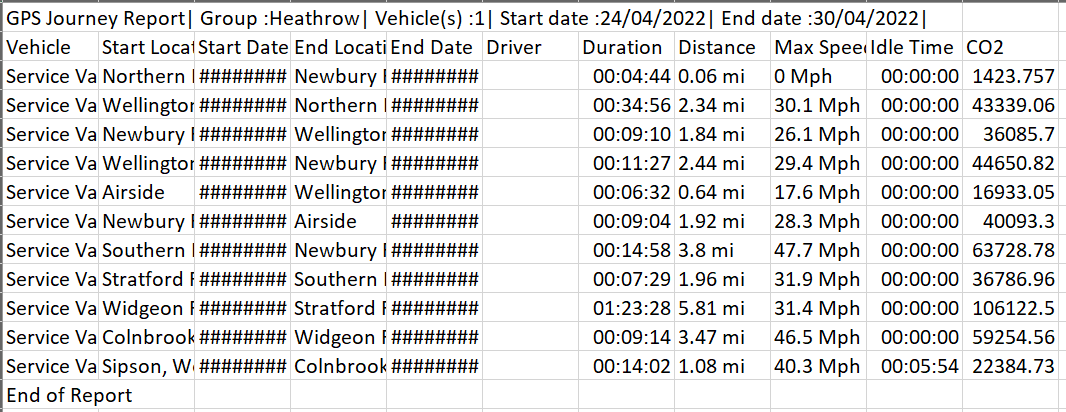
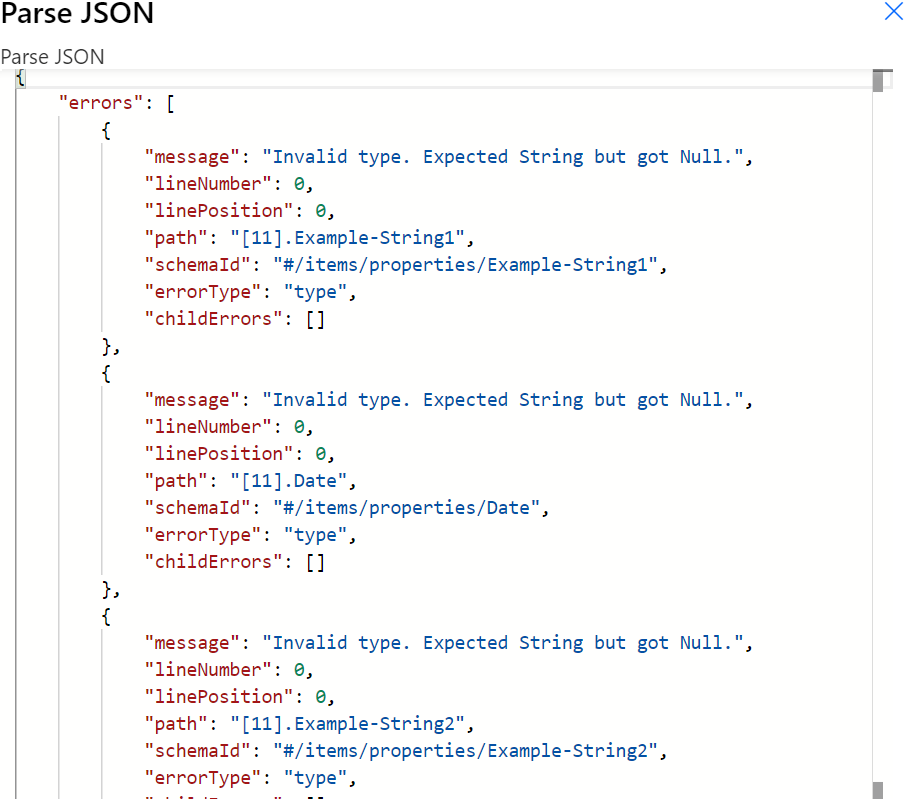
In my report on the last row there is an entry called 'End of Report' which from my limited knowledge looks as if it fails when it reaches Parse to JSON. Is there any way to deal with this? Obviously in an ideal world i would delete it but this report is generated from a 3rd party and I don't have that control.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@DickyFB
That may be because the Parse JSON is marking several columns as required at the end of the schema and the last line is missing those columns.
Either way, there is an option in the 1st set-up action where you can designate the number of footer or ending rows to skip before it gets to the Parse JSON step.
Try changing that setting to 1 or whatever number of ending rows you need to skip.

{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@takolota That worked like a charm.
Really appreciate your help and effort with this code. You have me saved hours of work.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Takolota, I'm new to this and I'm not sure how to import/test your flow in Power Automate? I would really appreciate your help!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This documentation may help: https://powerautomate.microsoft.com/en-us/blog/import-export-bap-packages/
You’ll need to download one of the flow zip files on previous posts, then go to Power Automate, then click the import button & follow the instructions in the documentation.
Once you’ve done that, you should be able to refresh your list of flows & the new imported flow will appear.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Everyone,
Microsoft Power Platform & @Paulie78 recently did a video demonstration of how to handle CSV & other files in dataflows: https://youtu.be/8IvHxRnwJ7Q
This looks like a more well-tested solution with many additional data transformation options. The dataflows connector looks to be non-premium so if you have access to it, then I suggest using it.
This custom-build flow-only solution may be helpful for those without access to the right Power Apps environment & maybe some other minor edge cases, but this looks like the way forward for most people.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
+1 on the DataFlow and PowerQuery solutions for DataVerse needs.
After experimenting for a few days, its exciting to see how easy it can be to massage data and then dump in to the DataVerse.
Biggest challenge was stopping to understand how the permissions are enabled/modified for other staff.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just found something that really should have been mentioned in that dataflows video. It currently only uploads to dataverse or to dataverse for teams.
Of course they only provided a half solution.